Publications Sebastian Ewert
Google Scholar, Arxiv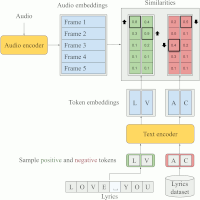 | Simon Durand, Daniel Stoller, and Sebastian Ewert Contrastive Learning-Based Audio to Lyrics Alignment for Multiple Languages Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Rhodes Island, Greece, pp. 1-5, 2023. Best Industry Paper at ICASSP 2023 [pdf] [published version] [bib] [code/demo] [abstract]  Lyrics alignment gained considerable attention in recent years. State-of-the-art systems either re-use established speech recognition toolkits, or design end-to-end solutions involving a Connectionist Temporal Classification (CTC) loss. However, both approaches suffer from specific weaknesses: toolkits are known for their complexity, and CTC systems use a loss designed for transcription which can limit alignment accuracy. In this paper, we use instead a contrastive learning procedure that derives cross-modal embeddings linking the audio and text domains. This way, we obtain a novel system that is simple to train end-to-end, can make use of weakly annotated training data, jointly learns a powerful text model, and is tailored to alignment. The system is not only the first to yield an average absolute error below 0.2 seconds on the standard Jamendo dataset but it is also robust to other languages, even when trained on English data only. Finally, we release word-level alignments for the JamendoLyrics Multi-Lang dataset. |
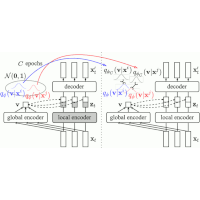 | Yin-Jyun Luo, Sebastian Ewert, and Simon Dixon Towards Robust Unsupervised Disentanglement of Sequential Data - A Case Study Using Music Audio Proceedings of the International Joint Conference on Artiticial Intelligence (IJCAI), Vienna, Austria, pp. 3299-3305, 2022. [pdf] [published version] [bib] [code/demo] [abstract] Disentangled sequential autoencoders (DSAEs) represent a class of probabilistic graphical models that describes an observed sequence with dynamic latent variables and a static latent variable. The former encode information at a frame rate identical to the observation, while the latter globally governs the entire sequence. This introduces an inductive bias and facilitates unsupervised disentanglement of the underlying local and global factors. In this paper, we show that the vanilla DSAE suffers from being sensitive to the choice of model architecture and capacity of the dynamic latent variables, and is prone to collapse the static latent variable. As a countermeasure, we propose TS-DSAE, a two-stage training framework that first learns sequence-level prior distributions, which are subsequently employed to regularise the model and facilitate auxiliary objectives to promote disentanglement. The proposed framework is fully unsupervised and robust against the global factor collapse problem across a wide range of model configurations. It also avoids typical solutions such as adversarial training which usually involves laborious parameter tuning, and domain-specific data augmentation. We conduct quantitative and qualitative evaluations to demonstrate its robustness in terms of disentanglement on both artificial and real-world music audio datasets. |
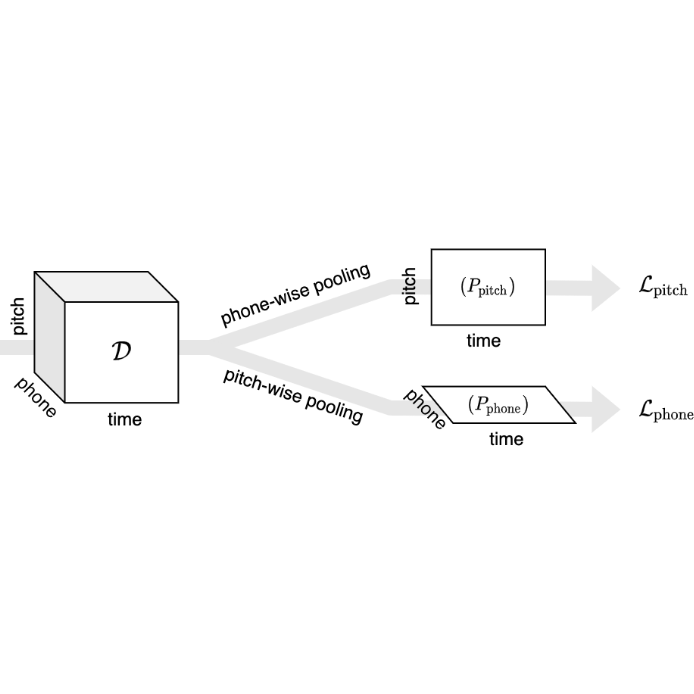 | Jiawen Huang, Emmanouil Benetos, and Sebastian Ewert Improving Lyrics Alignment through Joint Pitch Detection Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, pp. 451-455, 2022. [pdf] [published version] [bib] [code/demo] [abstract] In recent years, the accuracy of automatic lyrics alignment methods has increased considerably. Yet, many current approaches employ frameworks designed for automatic speech recognition (ASR) and do not exploit properties specific to music. Pitch is one important musical attribute of singing voice but it is often ignored by current systems as the lyrics content is considered independent of the pitch. In practice, however, there is a temporal correlation between the two as note starts often correlate with phoneme starts. At the same time the pitch is usually annotated with high temporal accuracy in ground truth data while the timing of lyrics is often only available at the line (or word) level. In this paper, we propose a multi-task learning approach for lyrics alignment that incorporates pitch and thus can make use of a new source of highly accurate temporal information. Our results show that the accuracy of the alignment result is indeed improved by our approach. As an additional contribution, we show that integrating boundary detection in the forced-alignment algorithm reduces cross-line errors, which improves the accuracy even further. |
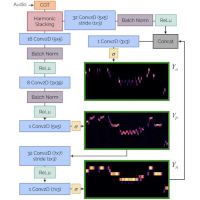 | Rachel M. Bittner, Juan José Bosch, David Rubinstein, Gabriel Meseguer-Brocal, and Sebastian Ewert A Lightweight Instrument-Agnostic Model for Polyphonic Note Transcription and Multipitch Estimation Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, pp. 781-785, 2022. [pdf] [published version] [bib] [code/demo] [abstract] Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise $f_0$ values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems. |
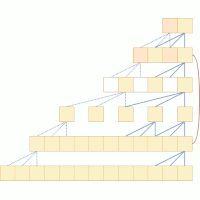 | Daniel Stoller, Mi Tian, Sebastian Ewert, and Simon Dixon Seq-U-Net: A One-Dimensional Causal U-Net for Efficient Sequence Modelling Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Yokohama, Japan, pp. 2893-2900, 2020. [pdf] [published version] [bib] [code/demo] [abstract] Convolutional neural networks (CNNs) with dilated filters such as the Wavenet or the Temporal Convolutional Network (TCN) have shown good results in a variety of sequence modelling tasks. While their receptive field grows exponentially with the number of layers, computing the convolutions over very long sequences of features in each layer is time and memory-intensive, and prohibits the use of longer receptive fields in practice. To increase efficiency, we make use of the ``slow feature'' hypothesis stating that many features of interest are slowly varying over time. For this, we use a U-Net architecture that computes features at multiple time-scales and adapt it to our auto-regressive scenario by making convolutions causal. We apply our model (``Seq-U-Net'') to a variety of tasks including language and audio generation. In comparison to TCN and Wavenet, our network consistently saves memory and computation time, with speed-ups for training and inference of over 4x in the audio generation experiment in particular, while achieving a comparable performance on real-world tasks. |
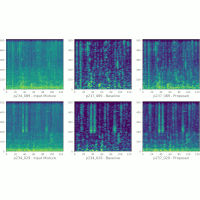 | Ishwarya Ananthabhotla, Sebastian Ewert, and Joseph A. Paradiso Using a Neural Network Codec Approximation Loss to Improve Source Separation Performance in Limited Capacity Networks Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, pp. 1-7, 2020. [pdf] [published version] [bib] [abstract] A growing need for on-device machine learning has led to an increased interest in light-weight neural networks that lower model complexity while retaining performance. While a variety of general-purpose techniques exist in this context, very few approaches exploit domain-specific properties to further improve upon the capacity-performance trade-off. In this paper, extending our prior work \cite{acmmm}, we train a network to emulate the behaviour of an audio codec and use this network to construct a loss. By approximating the psychoacoustic model underlying the codec, our approach enables light-weight neural networks to focus on perceptually relevant properties without wasting their limited capacity on imperceptible signal components. We adapt our method to two audio source separation tasks, demonstrate an improvement in performance for small-scale networks via listening tests, characterize the behaviour of the loss network in detail, and quantify the relationship between performance gain and model capacity. Our work illustrates the potential for incorporating perceptual principles into objective functions for neural networks. |
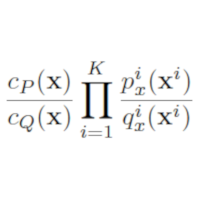 | Daniel Stoller, Sebastian Ewert, and Simon Dixon Training Generative Adversarial Networks from Incomplete Observations using Factorised Discriminators Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 2020. [pdf] [published version] [bib] [code/demo] [abstract] Generative adversarial networks (GANs) have shown great success in applications such as image generation and inpainting. However, they typically require large datasets, which are often not available, especially in the context of prediction tasks such as image segmentation that require labels. Therefore, methods such as the CycleGAN use more easily available unlabelled data, but do not offer a way to leverage additional labelled data for improved performance. To address this shortcoming, we show how to factorise the joint data distribution into a set of lower-dimensional distributions along with their dependencies. This allows splitting the discriminator in a GAN into multiple "sub-discriminators" that can be independently trained from incomplete observations. Their outputs can be combined to estimate the density ratio between the joint real and the generator distribution, which enables training generators as in the original GAN framework. We apply our method to image generation, image segmentation and audio source separation, and obtain improved performance over a standard GAN when additional incomplete training examples are available. For the Cityscapes segmentation task in particular, our method also improves accuracy by an absolute 14.9% over CycleGAN while using only 25 additional paired examples. |
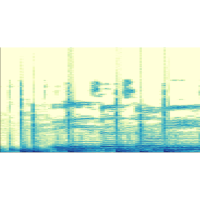 | Ishwarya Ananthabhotla, Sebastian Ewert, and Joseph A. Paradiso Towards a Perceptual Loss: Using a Neural Network Codec Approximation as a Loss for Generative Audio Models Proceedings of the ACM International Conference on Multimedia (ACM MM), Nice, France, pp. 1518-1525, 2019. [pdf] [published version] [bib] [code/demo] [abstract] Generative audio models based on neural networks have led to considerable improvements across fields including speech enhancement, source separation, and text-to-speech synthesis. These systems are typically trained in a supervised fashion using simple element-wise l1 or l2 losses. However, because they do not capture properties of the human auditory system, such losses encourage modelling perceptually meaningless aspects of the output, wasting capacity and limiting performance. Additionally, while adversarial models have been employed to encourage outputs that are statistically indistinguishable from ground truth and have resulted in improvements in this regard, such losses do not need to explicitly model perception as their task; furthermore, training adversarial networks remains an unstable and slow process. In this work, we investigate an idea fundamentally rooted in psychoacoustics. We train a neural network to emulate an MP3 codec as a differentiable function. Feeding the output of a generative model through this MP3 function, we remove signal components that are perceptually irrelevant before computing a loss. To further stabilize gradient propagation, we employ intermediate layer outputs to define our loss, as found useful in image domain methods. Our experiments using an autoencoding task show an improvement over standard losses in listening tests, indicating the potential of psychoacoustically motivated models for audio generation. |
 | Andreas Jansson, Rachel M. Bittner, Sebastian Ewert, and Tillman Weyde Joint Singing Voice Separation and F0 Estimation with Deep U-Net Architectures Proceedings of the European Signal Processing Conference (EUSIPCO), Coruna, Spain, pp. 1-5, 2019. [pdf] [published version] [bib] [abstract] Vocal source separation and fundamental frequency estimation in music are tightly related tasks. The outputs of vocal source separation systems have previously been used as inputs to vocal fundamental frequency estimation systems; conversely, vocal fundamental frequency has been used as side information to improve vocal source separation. In this paper, we propose several different approaches for jointly separating vocals and estimating fundamental frequency. We show that joint learning is advantageous for these tasks, and that a stacked architecture which first performs vocal separation outperforms the other configurations considered. Furthermore, the best joint model achieves state-of-the-art results for vocal-f0 estimation on the iKala dataset. Finally, we highlight the importance of performing polyphonic, rather than monophonic vocal-f0 estimation for many real-world cases. |
 | Emmanouil Benetos, Simon Dixon, Zhiyao Duan, and Sebastian Ewert Automatic Music Transcription: An Overview IEEE Signal Processing Magazine, vol. 36, no. 1, pp. 20-30, 2019. [pdf] [published version] [bib] [abstract] The capability of transcribing music audio into music notation is a fascinating example of human intelligence. It involves perception (analyzing complex auditory scenes), cognition (recognizing musical objects), knowledge representation (forming musical structures), and inference (testing alternative hypotheses). Automatic music transcription (AMT), i.e., the design of computational algorithms to convert acoustic music signals into some form of music notation, is a challenging task in signal processing and artificial intelligence. It comprises several subtasks, including multipitch estimation (MPE), onset and offset detection, instrument recognition, beat and rhythm tracking, interpretation of expressive timing and dynamics, and score typesetting. |
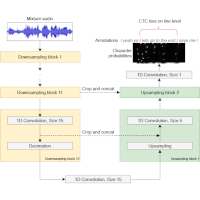 | Daniel Stoller, Simon Durand, and Sebastian Ewert End-to-end Lyrics Alignment for Polyphonic Music Using An Audio-to-Character Recognition Model Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, pp. 181-185, 2019. [pdf] [published version] [bib] [abstract] Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form. Here, we present a novel system based on a modified Wave-U-Net architecture, which predicts character probabilities directly from raw audio using learnt multi-scale representations of the various signal components. There are no sub-modules whose interdependencies need to be optimized. Our training procedure is designed to work with weak, line-level annotations available in the real world. With a mean alignment error of 0.35s on a standard dataset our system outperforms the state-of-the-art by an order of magnitude. |
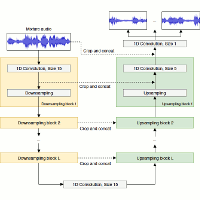 | Daniel Stoller, Sebastian Ewert, and Simon Dixon Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Paris, France, pp. 334-340, 2018. [pdf] [published version] [bib] [code/demo] [abstract] Models for audio source separation usually operate on the magnitude spectrum, which ignores phase information and makes separation performance dependant on hyper-parameters for the spectral front-end. Therefore, we investigate end-to-end source separation in the time-domain, which allows modelling phase information and avoids fixed spectral transformations. Due to high sampling rates for audio, employing a long temporal input context on the sample level is difficult, but required for high quality separation results because of long-range temporal correlations. In this context, we propose the Wave-U-Net, an adaptation of the U-Net to the one-dimensional time domain, which repeatedly resamples feature maps to compute and combine features at different time scales. We introduce further architectural improvements, including an output layer that enforces source additivity, an upsampling technique and a context-aware prediction framework to reduce output artifacts. Experiments for singing voice separation indicate that our architecture yields a performance comparable to a state-of-the-art spectrogram-based U-Net architecture, given the same data. Finally, we reveal a problem with outliers in the currently used SDR evaluation metrics and suggest reporting rank-based statistics to alleviate this problem. |
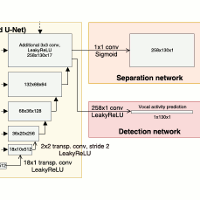 | Daniel Stoller, Sebastian Ewert, and Simon Dixon Jointly Detecting and Separating Singing Voice: A Multi-Task Approach Proceedings of the International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA), Guildford, UK, pp. 329-339, 2018. [pdf] [published version] [bib] [abstract] A main challenge in applying deep learning to music processing is the availability of training data. One potential solution is Multi-task Learning, in which the model also learns to solve related auxiliary tasks on additional datasets to exploit their correlation. While intuitive in principle, it can be challenging to identify related tasks and construct the model to optimally share information between tasks. In this paper, we explore vocal activity detection as an additional task to stabilise and improve the performance of vocal separation. Further, we identify problematic biases specific to each dataset that could limit the generalisation capability of separation and detection models, to which our proposed approach is robust. Experiments show improved performance in separation as well as vocal detection compared to single-task baselines. However, we find that the commonly used Signal-to-Distortion Ratio (SDR) metrics did not capture the improvement on non-vocal sections, indicating the need for improved evaluation methodologies. |
 | Daniel Stoller, Sebastian Ewert, and Simon Dixon Adversarial Semi-Supervised Audio Source Separation applied to Singing Voice Extraction Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, Canada, pp. 2391-2395, 2018. [pdf] [published version] [bib] [code/demo] [abstract] The state of the art in music source separation employs neural networks trained in a supervised fashion on multi-track databases to estimate the sources from a given mixture. With only few datasets available, often extensive data augmentation is used to combat overfitting. Mixing random tracks, however, can even reduce separation performance as instruments in real music are strongly correlated. The key concept in our approach is that source estimates of an optimal separator should be indistinguishable from real source signals. Based on this idea, we drive the separator towards outputs deemed as realistic by discriminator networks that are trained to tell apart real from separator samples. This way, we can also use unpaired source and mixture recordings without the drawbacks of creating unrealistic music mixtures. Our framework is widely applicable as it does not assume a specific network architecture or number of sources. To our knowledge, this is the first adoption of adversarial training for music source separation. In a prototype experiment for singing voice separation, separation performance increases with our approach compared to purely supervised training. |
 | Delia Fano Yela, Sebastian Ewert, Ken O'Hanlon, and Mark B. Sandler Shift-Invariant Kernel Additive Modelling for Audio Source Separation Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, Canada, pp. 616-620, 2018. [pdf] [published version] [bib] [abstract] A major goal in blind source separation to identify and separate sources is to model their inherent characteristics. While most state-of-the-art approaches are supervised methods trained on large datasets, interest in non-data-driven approaches such as Kernel Additive Modelling (KAM) remains high due to their interpretability and adaptability. KAM performs the separation of a given source applying robust statistics on the time-frequency bins selected by a source-specific kernel function, commonly the K-NN function. This choice assumes that the source of interest repeats in both time and frequency. In practice, this assumption does not always hold. Therefore, we introduce a shift-invariant kernel function capable of identifying similar spectral content even under frequency shifts. This way, we can considerably increase the amount of suitable sound material available to the robust statistics. While this leads to an increase in separation performance, a basic formulation, however, is computationally expensive. Therefore, we additionally present acceleration techniques that lower the overall computational complexity. |
 | Siying Wang, Sebastian Ewert, and Simon Dixon Identifying Missing and Extra Notes in Piano Recordings Using Score-Informed Dictionary Learning IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 10, pp. 1877-1889, 2017. [pdf] [published version] [bib] [abstract] The goal of automatic music transcription (AMT) is to obtain a high-level symbolic representation of the notes played in a given audio recording. Despite being researched for several decades, current methods are still inadequate for many applications. To boost the accuracy in a music tutoring scenario, we exploit that the score to be played is specified and we only need to detect the differences to the actual performance. In contrast to previous work which uses score information for post-processing, we employ the score to construct a transcription method that is tailored to the given audio recording. By adapting a score-informed dictionary learning technique as used for source separation, we learn for each score pitch a spectral pattern describing the energy distribution of associated notes in the recording. In this paper, we identify several systematic weaknesses in our previous approach and introduce three extensions to improve its performance. Firstly, we extend our dictionary of spectral templates to a dictionary of variable-length spectro-temporal patterns. Secondly, we integrate the score information using soft rather than hard constraints, to better take into account that differences from the score indeed occur. Thirdly, we introduce new regularizers to guide the learning process. Our experiments show that these extensions particularly improve the accuracy for identifying extra notes, while the accuracy for correct and missing notes remains at a similar level. The influence of each extension is demonstrated with further experiments. |
 | Sebastian Ewert and Mark B. Sandler An Augmented Lagrangian Method for Piano Transcription using Equal Loudness Thresholding and LSTM-based Decoding Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, pp. 146-150, 2017. [pdf] [published version] [bib] [abstract] A central goal in automatic music transcription is to detect individual note events in music recordings. An important variant is instrument-dependent music transcription where methods can use calibration data for the instruments in use. However, despite the additional information, results rarely exceed an f-measure of 80%. As a potential explanation, the transcription problem can be shown to be badly conditioned and thus relies on appropriate regularization. A recently proposed method employs a mixture of simple, convex regularizers (to stabilize the parameter estimation process) and more complex terms (to encourage more meaningful structure). In this paper, we present two extensions to this method. First, we integrate a computational loudness model to better differentiate real from spurious note detections. Second, we employ (Bidirectional) Long Short Term Memory networks to re-weight the likelihood of detected note constellations. Despite their simplicity, our two extensions lead to a drop of about 35% in note error rate compared to the state-of-the-art. |
 | Florian Thalmann, Sebastian Ewert, Geraint Wiggins, and Mark B. Sandler Exploring Musical Expression on the Web: Deforming, Exaggerating, and Blending Decomposed Recordings Proceedings of the Web Audio Conference (WAC), London, UK, pp. 1-6, 2017. [pdf] [published version] [bib] [code/demo] [abstract] We introduce a prototype of an educational web application for comparative performance analysis based on source separation and object-based audio techniques. The underlying system decomposes recordings of classical music performances into note events using score-informed source separation and represents the decomposed material using semantic web technologies. In a visual and interactive way, users can explore individual performances by highlighting specific musical aspects directly within the audio and by altering the temporal characteristics to obtain versions in which the micro-timing is exaggerated or suppressed. Multiple performances of the same work can be compared by juxtaposing and blending between the corresponding recordings. Finally, by adjusting the timing of events, users can generate intermediates of multiple performances to investigate their commonalities and differences. |
 | Qingyang Xi, Rachel M Bittner, Johan Pauwels, Sebastian Ewert, and Juan P. Bello Guitar-set Preview: A Dataset for Guitar Transcription and More International Society for Music Information Retrieval Conference (ISMIR) - Latebreaking, Suzhou, China, pp. 1-2, 2017. [pdf] [published version] [bib] [abstract] The guitar is a highly popular instrument for a variety of reasons, including its ability to produce polyphonic sound and its musical versatility. The resulting variability of sounds, however, poses significant challenges to auto- mated methods for analyzing guitar recordings. As data driven methods become increasingly popular for difficult problems like guitar transcription, sets of labeled data are highly valuable resources. In this paper we present a pre- view of the Guitar-Set dataset, which will provide high quality guitar recordings alongside rich annotations and metadata. In particular, by recording the instruments us- ing a hexaphonic pickup, we are able to not only provide recordings of the individual strings but also largely auto- mate the expensive annotation process. The dataset will contain recordings of both acoustic and electric guitars, as well as annotations including time-aligned string and fret positions, chords, beats, downbeats, and playing style. |
 | Delia Fano Yela, Sebastian Ewert, Derry FitzGerald, and Mark B. Sandler On the Importance of Temporal Context in Proximity Kernels: A Vocal Separation Case Study Proceedings of the AES International Conference on Semantic Audio, Erlangen, Germany, pp. 13-20, 2017. [pdf] [published version] [bib] [abstract] Musical source separation methods exploit source-specific spectral characteristics to facilitate the decomposition process. Kernel Additive Modelling (KAM) models a source applying robust statistics to time-frequency bins as specified by a source-specific kernel, a function defining similarity between bins. Kernels in existing approaches are typically defined using metrics between single time frames. In the presence of noise and other sound sources information from a single-frame, however, turns out to be unreliable and often incorrect frames are selected as similar. In this paper, we incorporate a temporal context into the kernel to provide additional information stabilizing the similarity search. Evaluated in the context of vocal separation, our simple extension led to a considerable improvement in separation quality compared to previous kernels. |
 | Sebastian Ewert and Mark B. Sandler Structured Dropout for Weak Label and Multi-Instance Learning and Its Application to Score-Informed Source Separation Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, USA, pp. 2277-2281, 2017. [pdf] [published version] [bib] [abstract] Many success stories involving deep neural networks are instances of supervised learning, where available labels power gradient-based learning methods. Creating such labels, however, can be expensive and thus there is increasing interest in weak labels which only provide coarse information, with uncertainty regarding time, location or value. Using such labels often leads to considerable challenges for the learning process. Current methods for weak-label training often employ standard supervised approaches that additionally reassign or prune labels during the learning process. The information gain, however, is often limited as only the importance of labels where the network already yields reasonable results is boosted. We propose treating weak-label training as an unsupervised problem and use the labels to guide the representation learning to induce structure. To this end, we propose two autoencoder extensions: class activity penalties and structured dropout. We demonstrate the capabilities of our approach in the context of score-informed source separation of music. |
 | Delia Fano Yela, Sebastian Ewert, Derry FitzGerald, and Mark B. Sandler Interference Reduction in Music Recordings Combining Kernel Additive Modelling and Non-Negative Matrix Factorization Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, USA, pp. 51-55, 2017. [pdf] [published version] [bib] [abstract] In live and studio recordings unexpected sound events often lead to interferences in the signal. For non-stationary interferences, sound source separation techniques can be used to reduce the interference level in the recording. In this context, we present a novel approach combining the strengths of two algorithmic families: NMF and KAM. The recent KAM approach applies robust statistics on frames selected by a source-specific kernel to perform source separation. Based on semi-supervised NMF, we extend this approach in two ways. First, we locate the interference in the recording based on detected NMF activity. Second, we improve the kernel-based frame selection by incorporating an NMF-based estimate of the clean music signal. Further, we introduce a temporal context in the kernel, taking some musical structure into account. Our experiments show improved separation quality for our proposed method over a state-of-the-art approach for interference reduction. |
 | Ken O’Hanlon, Sebastian Ewert, Johan Pauwels, and Mark B. Sandler Improved Template Based Chord Recognition Using the CRP Feature Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, USA, pp. 306-310, 2017. [pdf] [published version] [bib] [abstract] The task of chord recognition in music signals is often based upon pattern matching in chromagrams. Many variants of chroma exist and quality of chord recognition is related to the feature employed. Chroma Reduced Pitch (CRP) features are interesting in this context as they were designed to improve timbre invariance for the purpose of query retrieval. Their reapplication to chord recognition, however, has not been successful in previous studies. We consider that the default parametrisation of CRP attenuates some tonal information, as well as timbral, and consider alternatives to this default. We also provide a variant of a recently proposed compositional chroma feature, adapted for music pieces, rather than one instrument. Experiments described show improved results compared to existing features. |
 | Sebastian Ewert and Mark B. Sandler Piano Transcription in the Studio Using an Extensible Alternating Directions Framework IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 1983–1997, 2016. [pdf] [published version] [bib] [abstract] Given a musical audio recording, the goal of automatic music transcription is to determine a score-like representation of the piece underlying the recording. Despite significant interest within the research community, several studies have reported on a `glass ceiling' effect, an apparent limit on the transcription accuracy that current methods seem incapable of overcoming. In this paper, we explore how much this effect can be mitigated by focusing on a specific instrument class and making use of additional information on the recording conditions available in studio or home recording scenarios. In particular, exploiting the availability of single note recordings for the instrument in use we develop a novel signal model employing variable-length spectro-temporal patterns as its central building blocks - tailored for pitched percussive instruments such as the piano. Temporal dependencies between spectral templates are modeled, resembling characteristics of factorial scaled hidden Markov models (FS-HMM) and other methods combining Non-Negative Matrix Factorization with Markov processes. In contrast to FS-HMMs, our parameter estimation is developed in a global, relaxed form within the extensible alternating direction method of multipliers (ADMM) framework, which enables the systematic combination of basic regularizers propagating sparsity and local stationarity in note activity with more complex regularizers imposing temporal semantics. The proposed method achieves an f-measure of 93-95% for note onsets on pieces recorded on a Yamaha Disklavier (MAPS DB). |
 | Siying Wang, Sebastian Ewert, and Simon Dixon Robust and Efficient Joint Alignment of Multiple Musical Performances IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2132–2145, 2016. [pdf] [published version] [bib] [abstract] The goal of music alignment is to map each temporal position in one version of a piece of music to the corresponding positions in other versions of the same piece. Despite considerable improvements in recent years, state-of-the-art methods still often fail to identify a correct alignment if versions differ substantially with respect to acoustic conditions or musical interpretation. To increase the robustness for these cases, we exploit in this work the availability of multiple versions of the piece to be aligned. By processing these jointly, we can supply the alignment process with additional examples of how a section might be interpreted or which acoustic conditions may arise. This way, we can use alignment information between two versions transitively to stabilize the alignment with a third version. Extending our previous work, we present two such joint alignment methods, progressive alignment (PA) and probabilistic profile (PP), and discuss their fundamental differences and similarities on an algorithmic level. Our systematic experiments using 376 recordings of 9 pieces demonstrate that both methods can indeed improve the alignment accuracy and robustness over comparable pairwise methods. Further, we provide an in-depth analysis of the behaviour of both joint alignment methods, studying the influence of parameters such as the number of performances available, comparing their computational costs, and investigating further strategies to increase both their computational efficiency and alignment accuracy. |
 | Sebastian Ewert, Siying Wang, Meinard Müller, and Mark B. Sandler Score-Informed Identification of Missing and Extra Notes in Piano Recordings Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), New York, USA, pp. 30-36, 2016. [pdf] [published version] [bib] [abstract] A main goal in music tuition is to enable a student to play a score without mistakes, where common mistakes include missing notes or playing additional extra ones. To automatically detect these mistakes, a first idea is to use a music transcription method to detect notes played in an audio recording and to compare the results with a corresponding score. However, as the number of transcription errors produced by standard methods is often considerably higher than the number of actual mistakes, the results are often of limited use. In contrast, our method exploits that the score already provides rough information about what we seek to detect in the audio, which allows us to construct a tailored transcription method. In particular, we employ score-informed source separation techniques to learn for each score pitch a set of templates capturing the spectral properties of that pitch. After extrapolating the resulting template dictionary to pitches not in the score, we estimate the activity of each MIDI pitch over time. Finally, making again use of the score, we choose for each pitch an individualized threshold to differentiate note onsets from spurious activity in an optimized way. We indicate the accuracy of our approach on a dataset of piano pieces commonly used in education. |
 | Jonathan Driedger, Stefan Balke, Sebastian Ewert, and Meinard Müller Template-Based Vibrato Analysis in Music Signals Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), New York, USA, pp. 239-245, 2016. [pdf] [published version] [bib] [abstract] The automated analysis of vibrato in complex music signals is a highly challenging task. A common strategy is to proceed in a two-step fashion. First, a fundamental frequency (F0) trajectory for the musical voice that is likely to exhibit vibrato is estimated. In a second step, the trajectory is then analyzed with respect to periodic frequency modulations. As a major drawback, however, such a method cannot recover from errors made in the inherently difficult first step, which severely limits the performance during the second step. In this work, we present a novel vibrato analysis approach that avoids the first error-prone F0-estimation step. Our core idea is to perform the analysis directly on a signal's spectrogram representation where vibrato is evident in the form of characteristic spectro-temporal patterns. We detect and parameterize these patterns by locally comparing the spectrogram with a predefined set of vibrato templates. Our systematic experiments indicate that this approach is more robust than F0-based strategies. |
 | Francisco J. Rodriguez-Serrano, Sebastian Ewert, Pedro Vera-Candeas, and Mark B. Sandler A Score-Informed Shift-Invariant Extension of Complex Matrix Factorization for Improving the Separation of Overlapped Partials in Music Recordings Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Shanghai, China, pp. 61-65, 2016. [pdf] [published version] [bib] [abstract] Similar to non-negative matrix factorization (NMF), complex matrix factorization (CMF) can be used to decompose a given music recording into individual sound sources. In contrast to NMF, CMF models both the magnitude and phase of a source, which can improve the separation of overlapped partials. However, the shift-invariance for spectral templates enabling NMF-based methods to efficiently model vibrato in music is not available with CMF. Further, the estimation of an entire phase matrix for each source results in a high number of parameters in CMF, which often leads to poor local minima. In this paper we show that score information provides a source of prior knowledge rich enough to stabilize the CMF parameter estimation, without sacrificing its expressive power. As a second contribution, we present a shift-invariant extension to CMF bringing the vibrato-modeling capabilities of NMF to CMF. As our experiments demonstrate our proposed method consistently improves the separation quality for overlapped partials compared to score-informed NMF. |
 | Florian Thalmann, Sebastian Ewert, Mark B. Sandler, and Geraint A. Wiggins Spatially Rendering Decomposed Recordings - Integrating Score-Informed Source Separation and Semantic Playback Technologies International Society for Music Information Retrieval Conference (ISMIR) - Late-Breaking Session, Málaga, Spain, pp. 2, 2015. [pdf] [bib] [abstract] In this contribution, we present a system for creating novel renderings of a given music recording that aurally highlight certain musical aspects or semantics using spatial localizations. The system decomposes a monaural audio recording into separate events using score-informed source separation techniques and prepares them for an interactive mobile player that renders audio based on semantic information. We demonstrate the capabilities of the system by means of an example using an immersive chroma helix model which the listener can navigate in realtime using mobile sensor controls. |
 | Siying Wang, Sebastian Ewert, and Simon Dixon Compensating For Asynchronies Between Musical Voices In Score-Performance Alignment Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brisbane, Australia, pp. 589-593, 2015. Selected As Best Student Paper In Track: Audio and Acoustics Signal Processing (AASP) [pdf] [published version] [bib] [abstract] The goal of score-performance synchronisation is to align a given musical score to an audio recording of a performance of the same piece. A major challenge in computing such alignments is to account for musical parameters including the local tempo or playing style. To increase the overall robustness, current methods assume that notes occurring simultaneously in the score are played concurrently in a performance. Musical voices such as the melody, however, are often played asynchronously to other voices, which can lead to significant local alignment errors. In this paper, we present a novel method that handles asynchronies between the melody and the accompaniment by treating the voices as separate timelines in a multi-dimensional variant of dynamic time warping (DTW). Constraining the alignment with information obtained via classical DTW, our method measurably improves the alignment accuracy for pieces with asynchronous voices and preserves the accuracy otherwise. |
 | Sebastian Ewert, Mark D. Plumbley, and Mark B. Sandler A Dynamic Programming Variant Of Non-Negative Matrix Deconvolution For The Transcription Of Struck String Instruments Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brisbane, Australia, pp. 569-573, 2015. [pdf] [published version] [bib] [abstract] Given a musical audio recording, the goal of music transcription is to determine a score-like representation of the piece underlying the recording. Most current transcription methods employ variants of non-negative matrix factorization (NMF), which often fails to robustly model instruments producing non-stationary sounds. Using entire time-frequency patterns to represent sounds, non-negative matrix deconvolution (NMD) can capture certain types of non-stationary behavior but is only applicable if all sounds have the same length. In this paper, we present a novel method that combines the non-stationarity modeling capabilities available with NMD with the variable note lengths possible with NMF. Identifying frames in NMD patterns with states in a dynamical system, our method iteratively generates sound-object candidates separately for each pitch, which are then combined in a global optimization. We demonstrate the transcription capabilities of our method using piano pieces assuming the availability of single note recordings as training data. |
 | Siying Wang, Sebastian Ewert, and Simon Dixon Robust Joint Alignment of Multiple Versions of a Piece of Music Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Taipei, Taiwan, pp. 83–88, 2014. [pdf] [published version] [bib] [abstract] Large music content libraries often comprise multiple versions of a piece of music. To establish a link between different versions, automatic music alignment methods map each position in one version to a corresponding position in another version. Due to the leeway in interpreting a piece, any two versions can differ significantly, for example, in terms of local tempo, articulation, or playing style. For a given pair of versions, these differences can be significant such that even state-of-the-art methods fail to identify a correct alignment. In this paper, we present a novel method that increases the robustness for difficult to align cases. Instead of aligning only pairs of versions as done in previous methods, our method aligns multiple versions in a joint manner. This way, the alignment can be computed by comparing each version not only with one but with several versions, which stabilizes the comparison and leads to an increase in alignment robustness. Using recordings from the Mazurka Project, the alignment error for our proposed method was 14\% lower on average compared to a state-of-the-art method, with significantly less outliers (standard deviation 53\% lower). |
 | Sebastian Ewert, Bryan Pardo, Meinard Müller, and Mark D. Plumbley Score-Informed Source Separation for Musical Audio Recordings: An Overview IEEE Signal Processing Magazine, vol. 31, no. 3, pp. 116–124, 2014. [pdf] [published version] [bib] [code/demo] [abstract] In recent years, source separation has been a central research topic in music signal processing, with applications in stereo-to-surround up-mixing, remixing tools for DJs or producers, instrument-wise equalizing, karaoke systems, and pre-processing in music analysis tasks. Musical sound sources, however, are often strongly correlated in time and frequency, and without additional knowledge about the sources a decomposition of a musical recording is often infeasible. To simplify this complex task, various methods have been proposed in recent years which exploit the availability of a musical score. The additional instrumentation and note information provided by the score guides the separation process, leading to significant improvements in terms of separation quality and robustness. A major challenge in utilizing this rich source of information is to bridge the gap between high-level musical events specified by the score and their corresponding acoustic realizations in an audio recording. In this article, we review recent developments in score-informed source separation and discuss various strategies for integrating the prior knowledge encoded by the score. |
 | Jonathan Driedger, Meinard Müller, and Sebastian Ewert Improving Time-Scale Modification of Music Signals Using Harmonic-Percussive Separation IEEE Signal Processing Letters, vol. 21, no. 1, pp. 105–109, 2014. [pdf] [published version] [bib] [code/demo] [abstract] A major problem in time-scale modification (TSM) of music signals is that percussive transients are often perceptually degraded. To prevent this degradation, some TSM approaches try to explicitly identify transients in the input signal and to handle them in a special way. However, such approaches are problematic for two reasons. First, errors in the transient detection have an immediate influence on the final TSM result and, second, a perceptual transparent preservation of transients is by far not a trivial task. In this paper we present a TSM approach that handles transients implicitly by first separating the signal into a harmonic component as well as a percussive component which typically contains the transients. While the harmonic component is modified with a phase vocoder approach using a large frame size, the noise-like percussive component ismodified with a simple time-domain overlap-add technique using a short frame size, which preserves the transients to a high degree without any explicit transient detection. |
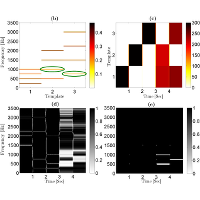 | Sebastian Ewert, Mark D. Plumbley, and Mark B. Sandler Accounting For Phase Cancellations In Non-Negative Matrix Factorization Using Weighted Distances Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, pp. 649–653, 2014. [pdf] [published version] [bib] [abstract] Techniques based on non-negative matrix factorization (NMF) have been successfully used to decompose a spectrogram of a music recording into a dictionary of templates and activations. While advanced NMF variants often yield robust signal models, there are usually some inaccuracies in the factorization %result since the underlying methods are not prepared for phase cancellations that occur when sounds with similar frequency are mixed. In this paper, we present a novel method that takes phase cancellations into account to refine dictionaries learned by NMF-based methods. Our approach exploits the fact that advanced NMF methods are often robust enough to provide information about how sound sources interact in a spectrogram, where they overlap, and thus where phase cancellations could occur. Using this information, the distances used in NMF are weighted entry-wise to attenuate the influence of regions with phase cancellations. Experiments on full-length, polyphonic piano recordings indicate that our method can be successfully used to refine NMF-based dictionaries. |
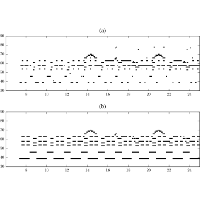 | Emmanouil Benetos, Sebastian Ewert, and Tillman Weyde Automatic Transcription Of Pitched And Unpitched Sounds From Polyphonic Music Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, pp. 3131–3135, 2014. [pdf] [published version] [bib] [code/demo] [abstract] Automatic transcription of polyphonic music has been an active research field for several years and is considered by many to be a key enabling technology in music signal processing. However, current transcription approaches either focus on detecting pitched sounds (from pitched musical instruments) or on detecting unpitched sounds (from drum kits). In this paper, we propose a method that jointly transcribes pitched and unpitched sounds from polyphonic music recordings. The proposed model extends the probabilistic latent component analysis algorithm and supports the detection of pitched sounds from multiple instruments as well as the detection of unpitched sounds from drum kit components, including bass drums, snare drums, cymbals, hi-hats, and toms. Our experiments based on polyphonic Western music containing both pitched and unpitched instruments led to very encouraging results in multi-pitch detection and drum transcription tasks. |
 | Matthias Mauch and Sebastian Ewert The Audio Degradation Toolbox And Its Application To Robustness Evaluation Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Curitiba, Brazil, pp. 83–88, 2013. [pdf] [published version] [bib] [code/demo] [abstract] We introduce the Audio Degradation Toolbox (ADT) for the controlled degradation of audio signals, and propose its usage as a means of evaluating and comparing the robustness of audio processing algorithms. Music recordings encountered in practical applications are subject to varied, sometimes unpredictable degradation. For example, audio is degraded by low-quality microphones, noisy recording environments, MP3 compression, dynamic compression in broadcasting or vinyl decay. In spite of this, no standard software for the degradation of audio exists, and music processing methods are usually evaluated against clean data. The ADT fills this gap by providing Matlab scripts that emulate a wide range of degradation types. We describe 14 degradation units, and how they can be chained to create more complex, 'real-world' degradations. The ADT also provides functionality to adjust existing ground-truth, correcting for temporal distortions introduced by degradation. Using four different music informatics tasks, we show that performance strongly depends on the combination of method and degradation applied. We demonstrate that specific degradations can reduce or even reverse the performance difference between two competing methods. ADT source code, sounds, impulse responses and definitions are freely available for download. |
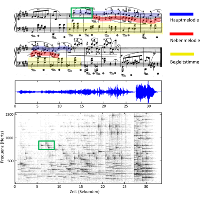 | Meinard Müller, Jonathan Driedger, and Sebastian Ewert Notentext-Informierte Quellentrennung für Musiksignale Proceedings of the Workshop Audiosignal- und Sprachverarbeitung (WASP) / GI-Jahrestagung, Koblenz, Germany, pp. 2928–2942, 2013. [pdf] [bib] [code/demo] [abstract] Die automatisierte Zerlegung von Musiksignalen in elementare Bestandteile stellt eine zentrale Aufgabe im Bereich der Musikverarbeitung dar. Hierbei geht es unter anderem um die Identifikation und Rekonstruktion von individuellen Melodie- und Instrumentalstimmen aus einer als Wellenform gegebenen Audioaufnahme -- eine Aufgabenstellung, die im \"ubergeordneten Bereich der Audiosignalverarbeitung auch als Quellentrennung bezeichnet wird. Im Fall von Musik weisen die Einzelstimmen typischer Weise starke zeitliche und spektrale \"Uberlappungen auf, was die Zerlegung in die Quellen ohne Zusatzwissen zu einem im Allgemeinen kaum l\"osbaren Problem macht. Zur Vereinfachung des Problems wurden in den letzten Jahren zahlreiche Verfahren entwickelt, bei denen neben dem Musiksignal auch die Kenntnis des zugrundeliegenden Notentextes vorausgesetzt wird. Die durch den Notentext gegebene Zusatzinformation zum Beispiel hinsichtlich der Instrumentierung und den vorkommenden Noten kann zur Steuerung des Quellentrennungsprozesses ausgenutzt werden, wodurch sich auch \"uberlappende Quellen zumindest zu einem gewissen Grad trennen lassen. Weiterhin lassen sich durch den Notentext die zu trennenden Stimmen oft erst spezifizieren. In diesem Artikel geben wir einen \"Uberblick \"uber neuere Entwicklungen im Bereich der Notentext-informierten Quellentrennung, diskutieren dabei allgemeine Herausforderungen bei der Verarbeitung von Musiksignalen, und skizzieren m\"ogliche Anwendungen. |
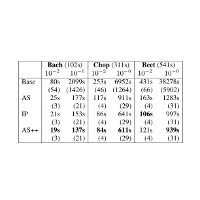 | Sebastian Ewert, Meinard Müller, and Mark B. Sandler Efficient Data Adaption For Musical Source Separation Methods Based On Parametric Models Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, Canada, pp. 46–50, 2013. [pdf] [published version] [bib] [abstract] The decomposition of a monaural audio recording into musically meaningful sound sources constitutes one of the central research topics in music signal processing. In this context, many recent approaches employ parametric models that describe a recording in a highly structured and musically informed way. However, a major drawback of such approaches is that the parameter learning process typically relies on computationally expensive data adaption methods. In this paper, the main idea is to distinguish parameters in which the model is linear explicitly from the remaining parameters. Exploiting the linearity we translate the data adaption problem into a sparse linear least squares problem with box constraints (SLLS-BC), a class of problems for which highly efficient numerical solvers exist. First experiments show that our approach based on modified SLLS-BC methods accelerates the data adaption by a factor of four or more compared to recently proposed methods. |
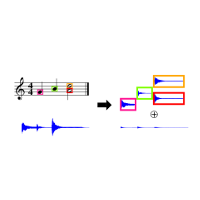 | Jonathan Driedger, Harald Grohganz, Thomas Prätzlich, Sebastian Ewert, and Meinard Müller Score-Informed Audio Decomposition and Applications Proceedings of the ACM International Conference on Multimedia (ACM-MM), Barcelona, Spain, pp. 541–544, 2013. [pdf] [published version] [bib] [code/demo] [abstract] The separation of different sound sources from polyphonic music recordings constitutes a complex task since one has to account for different musical and acoustical aspects. In the last years, various score-informed procedures have been suggested where musical cues such as pitch, timing, and track information are used to support the source separation process. In this paper, we discuss a framework for decomposing a given music recording into note-wise audio events which serve as elementary building blocks. In particular, we introduce an interface that employs the additional score information to provide a natural way for a user to interact with these audio events. By simply selecting arbitrary note groups within the score a user can access, modify, or analyze corresponding events in a given audio recording. In this way, our framework not only opens up new ways for audio editing applications, but also serves as a valuable tool for evaluating and better understanding the results of source separation algorithms. |
 | György Fazekas, Sebastian Ewert, Alo Allik, Simon Dixon, and Mark B. Sandler Shared Open Vocabularies and Semantic Media International Society for Music Information Retrieval Conference (ISMIR) - Late-Breaking Session, Porto, Portugal, pp. 2, 2012. [pdf] [bib] [abstract] This paper presents two ongoing projects at the Centre for Digital Music, Queen Mary University of London. Both projects are investigating the benefits of common data representations when dealing with large collections of media. The Semantic Media project aims at establishing an open interdisciplinary research network with the goal of creating highly innovative media navigation tools, while the Shared Open Vocabulary for Audio Research and Retrieval (SOVARR) project builds on community involvement to improve existing tools and ontologies for MIR research. Common goals include bringing together experts with various research backgrounds and establishing open vocabularies in combination with semantic media technologies as viable tools for sustainable and interoperable workflows. In this paper, we summarise our projects as well as the results of the Shared Open Vocabularies session that took place at ISMIR 2012. |
 | Sebastian Ewert Signal Processing Methods for Music Synchronization, Audio Matching, and Source Separation 2012. [pdf] [published version] [bib] [abstract] The field of music information retrieval (MIR) aims at developing techniques and tools for organizing, understanding, and searching multimodal information in large music collections in a robust, efficient and intelligent manner. In this context, this thesis presents novel, content-based methods for music synchronization, audio matching, and source separation. In general, music synchronization denotes a procedure which, for a given position in one representation of a piece of music, determines the corresponding position within another representation. Here, the thesis presents three complementary synchronization approaches, which improve upon previous methods in terms of robustness, reliability, and accuracy. The first approach employs a late-fusion strategy based on multiple, conceptually different alignment techniques to identify those music passages that allow for reliable alignment results. The second approach is based on the idea of employing musical structure analysis methods in the context of synchronization to derive reliable synchronization results even in the presence of structural differences between the versions to be aligned. Finally, the third approach employs several complementary strategies for increasing the accuracy and time resolution of synchronization results. Given a short query audio clip, the goal of audio matching is to automatically retrieve all musically similar excerpts in different versions and arrangements of the same underlying piece of music. In this context, chroma-based audio features are a well-established tool as they possess a high degree of invariance to variations in timbre. This thesis describes a novel procedure for making chroma features even more robust to changes in timbre while keeping their discriminative power. Here, the idea is to identify and discard timbre-related information using techniques inspired by the well-known MFCC features, which are usually employed in speech processing. Given a monaural music recording, the goal of source separation is to extract musically meaningful sound sources corresponding, for example, to a melody, an instrument, or a drum track from the recording. To facilitate this complex task, one can exploit additional information provided by a musical score. Based on this idea, this thesis presents two novel, conceptually different approaches to source separation. Using score information provided by a given MIDI file, the first approach employs a parametric model to describe a given audio recording of a piece of music. The resulting model is then used to extract sound sources as specified by the score. As a computationally less demanding and easier to implement alternative, the second approach employs the additional score information to guide a decomposition based on non-negative matrix factorization (NMF). |
 | Sebastian Ewert and Meinard Müller Using Score-Informed Constraints For NMF-Based Source Separation Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Kyoto, Japan, pp. 129–132, 2012. [pdf] [published version] [bib] [code/demo] [abstract] Techniques based on non-negative matrix factorization (NMF) can be used to efficiently decompose a magnitude spectrogram into a set of template (column) vectors and activation (row) vectors. To better control this decomposition, NMF has been extended using prior knowledge and parametric models. In this paper, we present such an extended approach that uses additional score information to guide the decomposition process. Here, opposed to previous methods, our main idea is to impose constraints on both the template as well as the activation side. We show that using such double constraints results in musically meaningful decompositions similar to parametric approaches, while being computationally less demanding and easier to implement. Furthermore, additional onset constraints can be incorporated in a straightforward manner without sacrificing robustness. We evaluate our approach in the context of separating note groups (e.g. the left or right hand) from monaural piano recordings. |
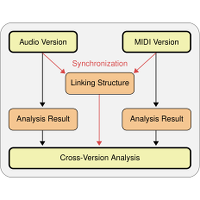 | Sebastian Ewert, Meinard Müller, Verena Konz, Daniel Müllensiefen, and Geraint Wiggins Towards Cross-Version Harmonic Analysis of Music IEEE Transactions on Multimedia, vol. 14, no. 3, pp. 770–782, 2012. [pdf] [published version] [bib] [abstract] For a given piece of music, there often exist multiple versions belonging to the symbolic (e.g. MIDI representations), acoustic (audio recordings), or visual (sheet music) domain. Each type of information allows for applying specialized, domain-specific approaches to music analysis tasks. In this paper, we formulate the idea of a cross-version analysis for comparing and/or combining analysis results from different representations. As an example, we realize this idea in the context of harmonic analysis to automatically evaluate MIDI-based chord labeling procedures using annotations given for corresponding audio recordings. To this end, one needs reliable synchronization procedures that automatically establish the musical relationship between the multiple versions of a given piece. This becomes a hard problem when there are significant local deviations in these versions. We introduce a novel late-fusion approach that combines different alignment procedures in order to identify reliable parts in synchronization results. Then, the cross-version comparison of the various chord labeling results is performed only on the basis of the reliable parts. Finally, we show how inconsistencies in these results across the different versions allow for a quantitative and qualitative evaluation, which not only indicates limitations of the employed chord labeling strategies but also deepens the understanding of the underlying music material. |
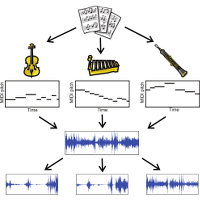 | Sebastian Ewert and Meinard Müller Score-Informed Source Separation for Music Signals Multimodal Music Processing, vol. 3, Dagstuhl, Germany, pp. 73–94, 2012. [pdf] [published version] [bib] [abstract] In recent years, the processing of audio recordings by exploiting additional musical knowledge has turned out to be a promising research direction. In particular, additional note information as specified by a musical score or a MIDI file has been employed to support various audio processing tasks such as source separation, audio parameterization, performance analysis, or instrument equalization. In this contribution, we provide an overview of approaches for scoreinformed source separation and illustrate their potential by discussing innovative applications and interfaces. Additionally, to illustrate some basic principles behind these approaches, we demonstrate how score information can be integrated into the well-known non-negative matrix factorization (NMF) framework. Finally, we compare this approach to advanced methods based on parametric models. |
 | Verena Thomas, Sebastian Ewert, and Michael Clausen Fast Intra-Collection Audio Matching Proceedings of the International ACM Workshop on Music Information Retrieval with User-Centered and Multimodal Strategies (MIRUM), Nara, Japan, pp. 1–6, 2012. [pdf] [bib] [code/demo] [abstract] The general goal of audio matching is to identify all audio extracts of a music collection that are similar to a given query snippet. Over the last years, several approaches to this task have been presented. However, due to the complexity of audio matching the proposed approaches usually either yield excellent matches but have a poor runtime or provide quick responses albeit calculate less satisfying retrieval results. In this paper, we present a novel procedure that combines the positive aspects and efficiently computes good retrieval results. Our idea is to exploit the fact that in some practical applications queries are not arbitrary audio snippets but are rather given as extracts from the music collection itself (intra-collection query). This allows us to split the audio collection into equal sized overlapping segments and to precompute their retrieval results using dynamic time warping (DTW). Storing these matches in appropriate index structures enables us to efficiently recombine them at runtime. Our experiments indicate a significant speedup compared to classical DTW-based audio retrieval while achieving nearly the same retrieval quality. |
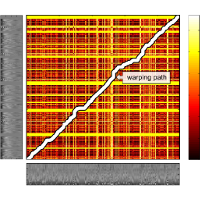 | David Damm, Harald Grohganz, Frank Kurth, Sebastian Ewert, and Michael Clausen SyncTS: Automatic synchronization of speech and text documents Proceedings of the AES International Conference Semantic Audio, Ilmenau, Germany, pp. 98–107, 2011. [pdf] [published version] [bib] [abstract] In this paper, we present an automatic approach for aligning speech signals to corresponding text documents. For this sake, we propose to first use text-to-speech synthesis (TTS) to obtain a speech signal from the textual representation. Subsequently, both speech signals are transformed to sequences of audio features which are then time-aligned using a variant of greedy dynamic time-warping (DTW). The proposed approach is both efficient (with linear running time), computationally simple, and does not rely on a prior training phase as it is necessary when using HMM-based approaches. It benefits from the combination of a) a novel type of speech feature, being correlated to the phonetic progression of speech, b) a greedy left-to-right variant of DTW, and c) the TTS-based approach for creating a feature representation from the input text documents. The feasibility of the proposed method is demonstrated in several experiments. |
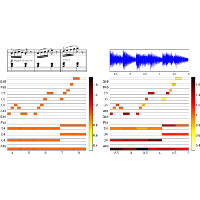 | Sebastian Ewert and Meinard Müller Estimating Note Intensities In Music Recordings Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Prague, Czech Republic, pp. 385–388, 2011. [pdf] [published version] [bib] [abstract] In this paper, we present automated methods for estimating note intensities in music recordings. Given a MIDI file (representing the score) and an audio recording (representing an interpretation) of a piece of music, our idea is to parametrize the spectrogram of the audio recording by exploiting the MIDI information and then to estimate the note intensities from the resulting model. The model is based on the idea of note-event spectrograms describing the part of a spectrogram that can be attributed to a given note event. After initializing our model with note events provided by the MIDI, we adapt all model parameters such that our model spectrogram approximates the audio spectrogram as accurately as possible. While note-wise intensity estimation is a very challenging task for general music, our experiments indicate promising results on polyphonic piano music. |
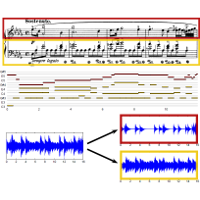 | Sebastian Ewert and Meinard Müller Score-Informed Voice Separation for Piano Recordings Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Miami, USA, pp. 245–250, 2011. [pdf] [published version] [bib] [code/demo] [abstract] The decomposition of a monaural audio recording into musically meaningful sound sources or voices constitutes a fundamental problem in music information retrieval. In this paper, we consider the task of separating a monaural piano recording into two sound sources (or voices) that correspond to the left hand and the right hand. Since in this scenario the two sources share many physical properties, sound separation approaches identifying sources based on their spectral envelope are hardly applicable. Instead, we propose a score-informed approach, where explicit note events specified by the score are used to parameterize the spectrogram of a given piano recording. This parameterization then allows for constructing two spectrograms considering only the notes of the left hand and the right hand, respectively. Finally, inversion of the two spectrograms yields the separation result. First experiments show that our approach, which involves high-resolution music synchronization and parametric modeling techniques, yields good results for real-world non-synthetic piano recordings. |
 | Meinard Müller and Sebastian Ewert Chroma Toolbox: MATLAB Implementations For Extracting Variants of Chroma-Based Audio Features Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Miami, USA, pp. 215–220, 2011. [pdf] [published version] [bib] [code/demo] [abstract] Chroma-based audio features, which closely correlate to the aspect of harmony, are a well-established tool in processing and analyzing music data. There are many ways of computing and enhancing chroma features, which results in a large number of chroma variants with different properties. In this paper, we present a chroma toolbox, which contains MATLAB implementations for extracting various types of recently proposed pitch-based and chroma-based audio features. Providing the MATLAB implementations on a well-documented website under a GNU-GPL license, our aim is to foster research in music information retrieval. As another goal, we want to raise awareness that there is no single chroma variant that works best in all applications. To this end, we discuss two example applications showing that the final music analysis result may crucially depend on the initial feature design step. |
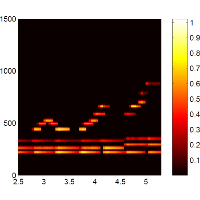 | Sebastian Ewert, Meinard Müller, and Michael Clausen Score-Informed Audio Parametrization International Society for Music Information Retrieval Conference (ISMIR) - Late-Breaking Session, Utrecht, Netherlands, pp. 1, 2010. [pdf] [bib] [abstract] In this contribution, we present automated methods for parameterizing audio recordings of piano music. In our scenario, we assume that we are given a MIDI file (representing the score) and an audio recording (representing an interpretation) of a piece of music. Then our idea is to successively adapt and enrich the information provided by the MIDI file to explain the given audio recording. More precisely, our goal is to parameterize the spectrogram of the audio recording by exploiting the score information (given as MIDI). This approach is inspired by Woodruff et al 2006, where score information is used to support the task of source separation. |
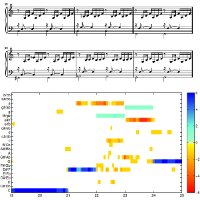 | Verena Konz, Meinard Müller, and Sebastian Ewert A Multi-Perspective Evaluation Framework for Chord Recognition Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Utrecht, Netherlands, pp. 9–14, 2010. [pdf] [published version] [bib] [abstract] The automated extraction of chord labels from audio recordings constitutes a major task in music information retrieval. To evaluate computer-based chord labeling procedures, one requires ground truth annotations for the underlying audio material. However, the manual generation of such annotations on the basis of audio recordings is tedious and time-consuming. On the other hand, trained musicians can easily derive chord labels from symbolic score data. In this paper, we bridge this gap by describing a procedure that allows for transferring annotations and chord labels from the score domain to the audio domain and vice versa. Using music synchronization techniques, the general idea is to locally warp the annotations of all given data streams onto a common time axis, which then allows for a cross-domain evaluation of the various types of chord labels. As a further contribution of this paper, we extend this principle by introducing a multi-perspective evaluation framework for simultaneously comparing chord recognition results over multiple performances of the same piece of music. The revealed inconsistencies in the results do not only indicate limitations of the employed chord labeling strategies but also deepen the understanding of the underlying music material. |
 | Sebastian Ewert, Meinard Müller, and Michael Clausen Musicmatching bei Variabilitäten in der Harmonik und Polyphonie Proceedings of the Deutsche Jahrestagung für Akustik (DAGA), Berlin, Germany, pp. 187–188, 2010. [pdf] [bib] [abstract] Im Jahr 1949 veröffentlichten Barlow und Morgenstern das \emph{Dictionary of Musical Themes}, welches erstmals ermöglichte, ein Musikstück anhand eines dazu gehörigen Themas zu identifizieren. Voraussetzung dazu sind jedoch detaillierte musikalische Kenntnisse, weshalb erst eine Automatisierung dieses Prozesses auch musikalischen Laien die Benutzung erlaubt. In diesem Kontext sind Musicmatching-Methoden von besonderer Bedeutung. Ziel dieser Methoden ist, bei Anfrage eines kurzen Musikausschnitts (in diesem Fall monophone Themen im MIDI Format) alle hierzu musikalisch ähnlichen Ausschnitte innerhalb von Musikaufnahmen zu identifzieren. Entscheidend ist dabei der Begriff der musikalischen Ähnlichkeit. So liefern klassische Musicmatching-Methoden auch dann korrekte Ergebnisse, wenn sich die Anfrage und der zu identifizierende Ausschnitt in Klangfarbe, Instrumentierung oder Dynamik unterscheiden. In dem hier vorgestellten Szenario ergeben sich aber darüber hinaus Unterschiede in Harmonik und Polyphonie, was mit klassischen Verfahren oftmals zu unbefriedigenden Resultaten führt. In diesem Beitrag präsentieren wir erste Ergebnisse unserer Analysen, mit denen wir das Ziel verfolgen, die Robustheit klassischer Verfahren gegenüber Harmonie- oder Polyphonieunterschieden zu erhöhen. Im nächsten Abschnitt betrachten wir dazu zunächst, welche prinzipiellen, musikalisch begründeten Probleme sich aus der Aufgabenstellung ergeben, Aufnahmen anhand von Themen zu identifizieren. Im Anschluss werden mehrere Musicmatching-Methoden vorgestellt und deren Ergebnisse kurz diskutiert. Im letzten Abschnitt fassen wir die Resultate zusammen und geben einen Ausblick auf zukünftige Arbeiten. |
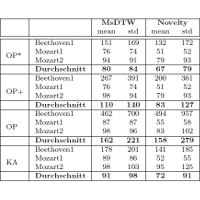 | Verena Thomas, Christian Fremerey, Sebastian Ewert, and Michael Clausen Notenschrift-Audio Synchronisation komplexer Orchesterwerke mittels Klavierauszug Proceedings of the Deutsche Jahrestagung für Akustik (DAGA), Berlin, Germany, pp. 191–192, 2010. [pdf] [bib] [abstract] Welcher Takt einer Partitur ist gerade in einer Einspielung des Musikstückes zu hören? Die Beantwortung dieser und ähnlicher Fragen ist Aufgabe der Notenschrift-Audio-Synchronisation. Einsatz finden solche Methoden beispielsweise zur Erleichterung der Navigation und Suche innerhalb von Musikstücken. Bisher wurden die entwickelten Verfahren für die Synchronisation von Partituren mit nicht zu komplexer Orchestrierung (hauptsächlich Klaviermusik) und entsprechenden Audioaufnahmen erprobt. Für komplexe Orchesterwerke ergeben sich bei der Notenschrift-Audio-Synchronisation jedoch neue Fragestellungen, von denen zwei in diesem Beitrag betrachtet werden sollen. |
 | Verena Konz, Meinard Müller, and Sebastian Ewert Ein Baseline-Experiment zur Klassifizierung von Problemen bei der Akkorderkennung Proceedings of the Deutsche Jahrestagung für Akustik (DAGA), Berlin, Germany, pp. 201–202, 2010. [pdf] [bib] [abstract] In den letzten Jahren hat die Akkorderkennung im Bereich der automatisierten Musikverarbeitunge in immer gr\”osseres Forschungsinteresse erlangt. Dies ist nicht verwunderlich, stellt doch die Harmonie ein grundlegendes Prinzip westlicher Musik dar. So ist ein Musikst\”uck wesentlich von seiner harmonischen Progression, der zeitlichen Abfolge verschiedener Akkorde, gepr\”agt. Hierbei versteht man unter einem Akkord den Zusammenklang verschiedener T\”one. Aufgrund dieser Basisfunktion der Harmonie f\”ur ein Musikst\”uck, dienen Akkordfolgen ausserdem als Zwischen-Merkmalsdarstellungen f\”ur andere Fragestellungen in der automatisierten Musikverarbeitung, wie z.B. die Segmentierung, die Indexierung oder die inhaltsbasierte Suche in Audiodatenbest\”anden. In diesem Beitrag wird ein template-basiertes Baseline-Verfahren zur Akkorderkennung vorgestellt und auf dem Audiodatenbestandderzw\”olf Studioalben der Beatles ausgewertet. Hierbei steht eine Klassifizierung von Problemen im Vordergrund, die bei der Akkorderkennung auftreten k\”onnen. In dem Zusammenhang wird explizit auf die Rolle des Tunings eingegangen und gezeigt, dass der Ausgleich von Tuningabweichungen einen wesentlichen Einfluss auf das Ergebnis der Akkord erkennung hat. |
 | Meinard Müller, Michael Clausen, Verena Konz, Sebastian Ewert, and Christian Fremerey A Multimodal Way of Experiencing and Exploring Music Interdisciplinary Science Reviews (ISR), vol. 35, no. 2, pp. 138–153, 2010. [pdf] [published version] [bib] [abstract] Significant digitization efforts have resulted in large multimodal music collections, which comprise music-related documents of various types and formats including text, symbolic data, audio, image, and video. The challenge is to organize, understand, and search musical content in a robust, efficient, and intelligent manner. Key issues concern the development of methods for analyzing, correlating, and annotating the available multimodal material, thus identifying and establishing semantic relationships across various music representations and formats. Here, one important task is referred to as music synchronization, which aims at identifying and linking semantically corresponding events present in different versions of the same underlying musical work. In this paper, we give an introduction to music synchronization and show how synchronization techniques can be integrated into novel user interfaces that allow music-lovers and researchers to access and explore music in all its different facets thus enhancing human involvement with music and deepening music understanding. |
 | Meinard Müller and Sebastian Ewert Towards Timbre-Invariant Audio Features for Harmony-Based Music IEEE Transactions on Audio, Speech, and Language Processing, vol. 18, no. 3, pp. 649–662, 2010. [pdf] [published version] [bib] [abstract] Chroma-based audio features are a well-established tool for analyzing and comparing harmony-based Western music that is based on the equal-tempered scale. By identifying spectral components that differ by a musical octave, chroma features possess a considerable amount of robustness to changes in timbre and instrumentation. In this paper, we describe a novel procedure that further enhances chroma features by significantly boosting the degree of timbre invariance without degrading the features' discriminative power. Our idea is based on the generally accepted observation that the lower mel-frequency cepstral coefficients (MFCCs) are closely related to timbre. Now, instead of keeping the lower coefficients, we discard them and only keep the upper coefficients. Furthermore, using a pitch scale instead of a mel scale allows us to project the remaining coefficients onto the twelve chroma bins. We present a series of experiments to demonstrate that the resulting chroma features outperform various state-of-the art features in the context of music matching and retrieval applications. As a final contribution, we give a detailed analysis of our enhancement procedure revealing the musical meaning of certain pitch-frequency cepstral coefficients. |
 | Sebastian Ewert, Meinard Müller, and Roger B. Dannenberg Towards Reliable Partial Music Alignments Using Multiple Synchronization Strategies Proceedings of the International Workshop on Adaptive Multimedia Retrieval (AMR), Lecture Notes in Computer Science (LNCS) vol. 6535, Madrid, Spain, pp. 35–48, 2009. [pdf] [published version] [bib] [abstract] The general goal of music synchronization is to align multiple information sources related to a given piece of music. This becomes a hard problem when the various representations to be aligned reveal significant differences not only in tempo, instrumentation, or dynamics but also in structure or polyphony. Because of the complexity and diversity of music data, one can not expect to find a universal synchronization algorithm that yields reasonable solutions in all situations. In this paper, we present a novel method that allows for automatically identifying the reliable parts of alignment results. Instead of relying on one single strategy, our idea is to combine several types of conceptually different synchronization strategies within an extensible framework, thus accounting for various musical aspects. Looking for consistencies and inconsistencies across the synchronization results, our method automatically classifies the alignments locally as reliable or critical. Considering only the reliable parts yields a high-precision partial alignment. Moreover, the identification of critical parts is also useful, as they often reveal musically interesting deviations between the versions to be aligned. |
 | Christian Fremerey, Michael Clausen, Sebastian Ewert, and Meinard Müller Sheet Music-Audio Identification Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Kobe, Japan, pp. 645–650, 2009. [pdf] [published version] [bib] [abstract] In this paper, we introduce and discuss the task of sheet music-audio identification. Given a query consisting of a sequence of bars from a sheet music representation, the task is to find corresponding sections within an audio interpretation of the same piece. Two approaches are proposed: a semi-automatic approach using synchronization and a fully automatic approach using matching techniques. A workflow is described that allows for evaluating the matching approach using the results of the more reliable synchronization approach. This workflow makes it possible to handle even complex queries from orchestral scores. Furthermore, we present an evaluation procedure, where we investigate several matching parameters and tempo estimation strategies. Our experiments have been conducted on a dataset comprising pieces of various instrumentations and complexity. |
 | Meinard Müller, Verena Konz, Andi Scharfstein, Sebastian Ewert, and Michael Clausen Towards Automated Extraction of Tempo Parameters from Expressive Music Recordings Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Kobe, Japan, pp. 69–74, 2009. [pdf] [published version] [bib] [abstract] A performance of a piece of music heavily depends on the musician's or conductor's individual vision and personal interpretation of the given musical score. As basis for the analysis of artistic idiosyncrasies, one requires accurate annotations that reveal the exact timing and intensity of the various note events occurring in the performances. In the case of audio recordings, this annotation is often done manually, which is prohibitive in view of large music collections. In this paper, we present a fully automatic approach for extracting temporal information from a music recording using score-audio synchronization techniques. This information is given in the form of a tempo curve that reveals the relative tempo difference between an actual performance and some reference representation of the underlying musical piece. As shown by our experiments on harmony-based Western music, our approach allows for capturing the overall tempo flow and for certain classes of music even finer expressive tempo nuances. |
 | Meinard Müller, Sebastian Ewert, and Sebastian Kreuzer Making Chroma Features More Robust To Timbre Changes Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Taipei, Taiwan, pp. 1877–1880, 2009. [pdf] [published version] [bib] [abstract] Chroma-based audio features are a well-established tool for analyzing and comparing music data. By identifying spectral components that differ by a musical octave, chroma features show a high degree of invariance to variations in timbre. In this paper, we describe a novel procedure for making chroma features even more robust to changes in timbre and instrumentation while keeping their discriminative power. Our idea is based on the generally accepted observation that the lower mel-frequency cepstral coefficients (MFCCs) are closely related to timbre. Now, instead of keeping the lower coefficients, we will discard them and only keep the upper coefficients. Furthermore, using a pitch scale instead of a mel scale allows us to project the remaining coefficients onto the twelve chroma bins. Our systematic experiments show that the resulting chroma features have indeed gained a significant boost towards timbre invariance. |
 | Sebastian Ewert, Meinard Müller, and Peter Grosche High Resolution Audio Synchronization Using Chroma Onset Features Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Taipei, Taiwan, pp. 1869–1872, 2009. [pdf] [published version] [bib] [code/demo] [abstract] The general goal of music synchronization is to automatically align the multiple information sources such as audio recordings, MIDI files, or digitized sheet music related to a given musical work. In computing such alignments, one typically has to face a delicate tradeoff between robustness and accuracy. In this paper, we introduce novel audio features that combine the high temporal accuracy of onset features with the robustness of chroma features. We show how previous synchronization methods can be extended to make use of these new features. We report on experiments based on polyphonic Western music demonstrating the improvements of our proposed synchronization framework. |
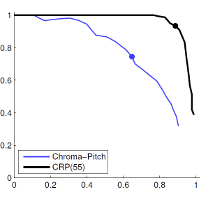 | Sebastian Ewert, Meinard Müller, and Michael Clausen Towards Timbre-Invariant Audio Features for Harmony-Based Music Proceedings of the International Conference on Acoustics (NAG/DAGA), Rotterdam, Netherlands, pp. 352–353, 2009. [pdf] [bib] [abstract] One main goal of content-based music analysis and retrieval is to reveal semantically meaningful relationships between different music excerpts contained in a given data collection. Here, the notion of similarity used to compare different music excerpts is a delicate issue and largely depends on the respective application. In particular, for detecting harmony-based relations, chroma features have turned out to be a powerful mid-level representation for comparing and relating music data in various realizations and formats. An important step of the chroma feature calculation is the grouping of spectral energy components that belong to the same pitch class or chroma of the equal tempered scale. Here, the octave identification introduces a high degree of invariance to changes in timbre and instrumentation. In particular, such features are useful in tasks such as cover song identification or audio matching, where one often has to deal with large variations in timbre and instrumentation between different versions of a single piece of music. In this paper, we introduce a strategy to further increase this invariance by combining the concept of chroma features with the well-known concept of mel-frequency cepstral coefficients (MFCCs). More precisely, recall that the mel-frequency cepstrum is obtained by taking a decorrelating cosine transform of a log power spectrum on a logarithmic mel scale. The lower MFCCs are known to capture information on timbre. Therefore, intuitively spoken, one should achieve some degree of timbre-invariance when discarding exactly this information. As our main contribution, we combine this idea with the concept of chroma features by first replacing the nonlinear mel scale by a nonlinear pitch scale. We then apply a cosine transform on the logarithmized pitch representation and only keep the upper coefficients, which are finally projected onto the twelve chroma bins to obtain a chroma representation. The technical details of this procedure are described in the next section. After that, we show how our novel features improve the matching quality between harmonically-related music excerpts contained in different versions and arrangements of the same piece of music. Conclusions and prospects on future work are given in the last section. |
 | Peter Grosche, Meinard Müller, and Sebastian Ewert Combination of Onset-Features with Applications to High-Resolution Music Synchronization Proceedings of the International Conference on Acoustics (NAG/DAGA), Rotterdam, Netherlands, pp. 357–360, 2009. [pdf] [bib] [abstract] Many different methods for the detection of note onsets in music recordings have been proposed and applied to tasks such as music transcription, beat tracking, tempo estimation, and music synchronization. Most of the proposed onset detectors rely on the fact that note onsets often go along with a sudden increase of the signal's energy, which particularly holds for instruments such as piano, guitar, or percussive instruments. Much more difficult is the detection of onsets in the case of more fluent note transitions, which is often the case for classical music dominated by string instruments. In this paper, we introduce improved novelty curves that yield good indications for note onsets even in the case of only smooth temporal and spectral intensity changes in the signal. We then show how these novelty curves can be used to significantly improve the temporal accuracy in music synchronization tasks. |
 | Sebastian Ewert, Meinard Müller, Daniel Müllensiefen, Michael Clausen, and Geraint A. Wiggins Case Study ``Beatles Songs'' – What can be Learned from Unreliable Music Alignments? Knowledge Representation for Intelligent Music Processing, no. 09051, 2009. [pdf] [published version] [bib] [abstract] As a result of massive digitization efforts and the world wide web, there is an exploding amount of available digital data describing and representing music at various semantic levels and in diverse formats. For example, in the case of the Beatles songs, there are numerous recordings including an increasing number of cover songs and arrangements as well as MIDI data and other symbolic music representations. The general goal of music synchronization is to align the multiple information sources related to a given piece of music. This becomes a difficult problem when the various representations reveal significant differences in structure and polyphony, while exhibiting various types of artifacts. In this paper, we address the issue of how music synchronization techniques are useful for automatically revealing critical passages with significant difference between the two versions to be aligned. Using the corpus of the Beatles songs as test bed, we analyze the kind of differences occurring in audio and MIDI versions available for the songs. |
 | Meinard Müller and Sebastian Ewert Joint Structure Analysis With Applications To Music Annotation And Synchronization Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Philadelphia, USA, pp. 389–394, 2008. [pdf] [published version] [bib] [abstract] The general goal of music synchronization is to automatically align different versions and interpretations related to a given musical work. In computing such alignments, recent approaches assume that the versions to be aligned correspond to each other with respect to their overall global structure. However, in real-world scenarios, this assumption is often violated. For example, for a popular song there often exist various structurally different album, radio, or extended versions. Or, in classical music, different recordings of the same piece may exhibit omissions of repetitions or significant differences in parts such as solo cadenzas. In this paper, we introduce a novel approach for automatically detecting structural similarities and differences between two given versions of the same piece. The key idea is to perform a single structural analysis for both versions simultaneously instead of performing two separate analyses for each of the two versions. Such a joint structure analysis reveals the repetitions within and across the two versions. As a further contribution, we show how this information can be used for deriving musically meaningful partial alignments and annotations in the presence of structural variations. |
 | Sebastian Ewert and Meinard Müller Refinement Strategies for Music Synchronization Proceedings of the International Symposium on Computer Music Modeling and Retrieval (CMMR), Lecture Notes in Computer Science (LNCS), vol. 5493, Copenhagen, Denmark, pp. 147–165, 2008. [pdf] [published version] [bib] [abstract] For a single musical work, there often exists a large number of relevant digital documents including various audio recordings, MIDI files, or digitized sheet music. The general goal of music synchronization is to automatically align the multiple information sources related to a given musical work. In computing such alignments, one typically has to face a delicate tradeoff between robustness, accuracy, and efficiency. In this paper, we introduce various refinement strategies for music synchronization. First, we introduce novel audio features that combine the temporal accuracy of onset features with the robustness of chroma features. Then, we show how these features can be used within an efficient and robust multiscale synchronization framework. In addition we introduce an interpolation method for further increasing the temporal resolution. Finally, we report on our experiments based on polyphonic Western music demonstrating the respective improvements of the proposed refinement strategies. |
 | Frank Kurth, Meinard Müller, Sebastian Ewert, and Michael Clausen Vektorquantisierung chromabasierter Audiomerkmale Proceedings of the Deutsche Jahrestagung für Akustik (DAGA), Dresden, Germany, pp. 557–558, 2008. [pdf] [bib] [abstract] Chromabasierte Audiomerkmale haben sich in den letzten Jahren als ein m\"achtiges Werkzeug zur Analyse von Musiksignalen erwiesen. Insbesondere konnten durch den Einsatz von Chromamerkmalen gro{\ss}e Fortschritte beim Audiomatching harmoniebasierter Musik erzielt werden. Das Ziel des Audiomatchings besteht darin, bei Anfrage eines kurzen Abschnitts einer CD-Aufnahme alle hierzu musikalisch \"ahnlichen Abschnitte innerhalb einer Kollektion von Musikaufnahmen zu identifizieren. Im Hinblick auf ein effizientes und auf gro{\ss}e Datenmassen skalierendes Verfahren ist die Möglichkeit zur Quantisierung und die damit verbundene Indexierbarkeit der Chromamerkmale sehr wichtig. In diesem Beitrag stellen wir zwei Methoden zur Chromaquantisierung vor. Die erste Methode basiert auf einem Clusteringansatz für den wir den bekannten LBG-Algorithmus geeignet adaptieren. Die zweite Methode nutzt semantisches Vorwissen über den Merkmalsraum aus, das sich aus dem auf der wohltemperierten Stimmung basierenden Harmoniekonzept f\"ur westliche Musik ergibt. Abschließend vergleichen wir die aus den beiden Methoden resultierenden Codeb\"ucher im Rahmen des indexbasierten Audiomatchings. |
 | Sebastian Ewert Effiziente Methoden zur hochauflösenden Musiksynchronisation 2007. [bib] |